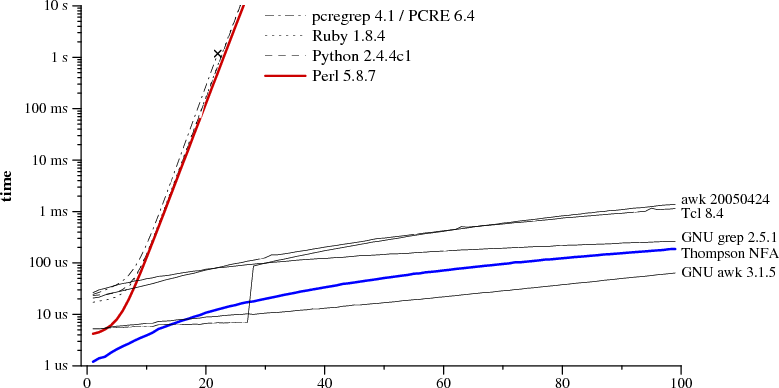
A correct implementation of regular expressions, using finite state automata rather than backtracking.
Most regex implementations (except for GNU grep, GNU awk and a few others) use
backtracking, which (while adding support for backreferences) massively reduces
the efficiency of the implementation. Even the best backtracking implementations
have O(2^n) time complexity in several cases.
On the other hand, by using finite state automata, regular expression matching
can have O(n) time complexity (or possibly superlinear, if the implementation
uses NFAs and doesn't cache them to produce DFAs). In either case, the
differences can be quite drastic:
To use this, you just need to do the following:
>>> import redone
>>>
>>> pattern = "some pattern here"
>>> string = "some string here"
>>>
>>> # Pre-compiled version (recommended).
>>> r = redone.compile(pattern)
>>> r.match(string)
# <RegexMatch(...) ...>
>>> r.fullmatch(string)
# <RegexMatch(...) ...>
>>> r.search(string)
# <RegexMatch(...) ...>
>>> r.findall(string)
# [<RegexMatch(...) ...>, ...]
>>> r.finditer(string)
# <generator object ...>
>>> r.sub("replacement", string)
# "replaced string"
>>>
>>> # On-the-fly version.
>>> redone.match(pattern, string)
# <RegexMatch(...) ...>
>>> redone.fullmatch(pattern, string)
# <RegexMatch(...) ...>
>>> redone.search(pattern, string)
# <RegexMatch(...) ...>
>>> redone.findall(pattern, string)
# [<RegexMatch(...) ...>, ...]
>>> redone.finditer(pattern, string)
# <generator object ...>
>>> redone.sub(pattern, "replacement", string)
# "replaced string"The following features are still "in the works":
- Proper UTF-8 support (the regex alphabet only includes
string.printable). - Flags (mainly case insensitivity).
- Submatch extraction.
- Assertions (
^,$,\band the like). - Character class ranges (because apparently they are used a lot).
The following features are likely not to be implemented:
- ASCII escape sequences (there's no need, just embed them in the pattern).
- POSIX "special" character classes (
[:alnum:]), just use character classes. - Backreferences. Since implementing them in NFAs with polynomial time is NP-complete, the only solution is to use backtracking in that one case (which would massively complicate the codebase).
The redone regular expression language currently contains the following
features:
- Wildcard matching (
.). - Unions (
a|b). - Character sets (
[abc][^def]). - Regex grouping (
(ab(c))). - Repetition (
a?b*c+). - Counted repetition (
a{2}b{3,}c{4,5}).
- This was made in order to prove a point (and as a programming exercise).
Python's mantra is that it is "fast enough", so the backtracking approach used
by
reseems to match that. Also, I'd argue that using the well-testedremodule is much safer than using an implementation some random on the internet wrote, and that the speed issue isn't a big deal on most regular expressions. - While finite state automata are theoretically faster than backtracking, in
practice, the C code written is better optimised for common patterns and is
better tested. That doesn't mean that the
remodule doesn't suffer from the "perl problem", it just means that (in most usecases) that isn't an issue. - Not suitable for programmers under the age of 3.